Azure Data Factory v1 で作成したジョブを日次バッチで動かすときの罠について説明します。
Azure Data Factory v1 でのトリガータイミングの指定画面は次のようになっています。
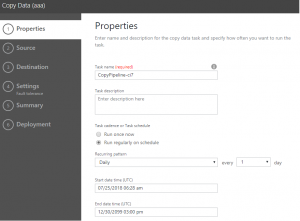
この画面では、Dailyでevery 1 day となっています。
Start date time (UTC)を指定するようになっています。
罠1 画面で日時(Daily)を選択すると必ずUTC12時に実行される
この画面だけ見ると、Start date time (UTC)で指定した時間に実行され、以後24時間おきに実行されるように見えます。
実際は、UTC12時、日本時間朝9時に実行されます。
ドキュメントを確認すると、以下のように記述されています。
既定では、毎日 ("frequency": "Day", "interval": 1) のスライスは UTC 時 12 AM (午前 0 時) に開始します。 開始時刻を 6 AM UTC にするには、次のスニペットに示すようにオフセットを設定します。
GUIで設定すると、Dailyの場合は必ず、UTC0時なので日本時間9時になります。
これを変更するには、Offsetを指定しないといけないのですが、画面からは指定できなくて、JSONを修正する必要があります。
罠2 JSON(Availability)を更新して、offsetを追加しようとするとサポートしてないとエラーがでる
offsetを指定して更新しようとすると、次のようなエラーが出ます。
Updating the availability section of a Dataset is not supported. Existing availability configuration: Frequency=Day, Interval=1, AnchorDateTime=01/01/0001 00:00:00, Offset=06:00:00, Style=StartOfInterval, new availability configuration: Frequency=Day, Interval=1, AnchorDateTime=01/01/0001 00:00:00, Offset=07:00:00, Style=StartOfInterval.
機能提供されていませんよと……なんとまぁ。
ちなみに大昔に改善要望が出ています。
How can we improve Microsoft Azure Data Factory?
現時点で対応されていないですし、きっと今後も対応されないでしょうね。
設定するには、再作成してねっと案内されています。
「The work-around is to delete the datasets and related piplelines and re-create them with the new settings. 」
罠3 availabilityにOffsetを追加したら、activitiesのschedulerにも追加しないといけない
仕方ないので、Outputを消して再作成して、Offsetを追加しました。
すると今度は、PipelineのactivitiesのschedulerにもOffsetを追加しないとエラーになりました。
罠4 Start date time (UTC)に過去日を指定すると、そこを起点にスライスされて、複数処理されてしまう
再作成するから、オリジナルをコピペするじゃないですか?
そーすると当然StartTimeが以前の古い日付になってるじゃないですか?
怖いことが起こりそうです。
パイプラインには過去の開始日を設定できます。 設定した場合、Data Factory によって過去のすべてのデータ スライスが自動的に計算 (バックフィル) され、処理が開始されます。 たとえば、開始日が 2017-04-01 のパイプラインを作成し、現在の日付が 2017-04-10 だとします。 出力データセットのパターンが 1 日ごとの場合、開始日が過去であるため、Data Factory は 2017-04-01 から 2017-04-09 までのすべてのスライスの処理をすぐに開始します。
やめて、、、、、事故になる(汗
再作成するときには、ちゃんと、Pipelineの「Start」を適切な日付にしましょう。
結論 V2素晴らしい
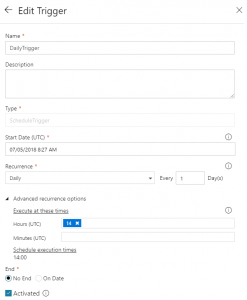
これがV2のトリガーの指定画面です。
日次で何時に実行するかというのがしっかりと指定できます。素晴らしい。