CosmosDBのスキーマー設計は、RMDBと異なる部分があります。 RMDBの感覚でスキーマー設計をすると、RUを大きく消費したり、性能がでないケースがあります。
MicrosoftのCosmosDBチームのGithubで公開されているCosmosDB-DataModeling.pptxと、アメリカで開催されたセミナーの内容をもとに書き起こし&意訳&追記したものをde:code 2019のパーソナルスポンサーの資料として公開しました。
SQL Azure と Cosmos DB をメインにWindows Azureの情報を発信
CosmosDBのスキーマー設計は、RMDBと異なる部分があります。 RMDBの感覚でスキーマー設計をすると、RUを大きく消費したり、性能がでないケースがあります。
MicrosoftのCosmosDBチームのGithubで公開されているCosmosDB-DataModeling.pptxと、アメリカで開催されたセミナーの内容をもとに書き起こし&意訳&追記したものをde:code 2019のパーソナルスポンサーの資料として公開しました。
Microsoft Ignightで、Azure SQL Database Hyperscaleが発表されました。
ドキドキが止まらないので、早速まとめてみました。
もう間も無く、2018/10/1からPublic Previewが開始されるようです。
GAは、いつだろー?
vCoreモデルをベースとしているのでDTUモデルでは使用できません。
マイグレーションなどは、インスタンスサイズ変更と同等の手順で実施できるようになるようです。
下のスライドのスクリーンショットをみてください。
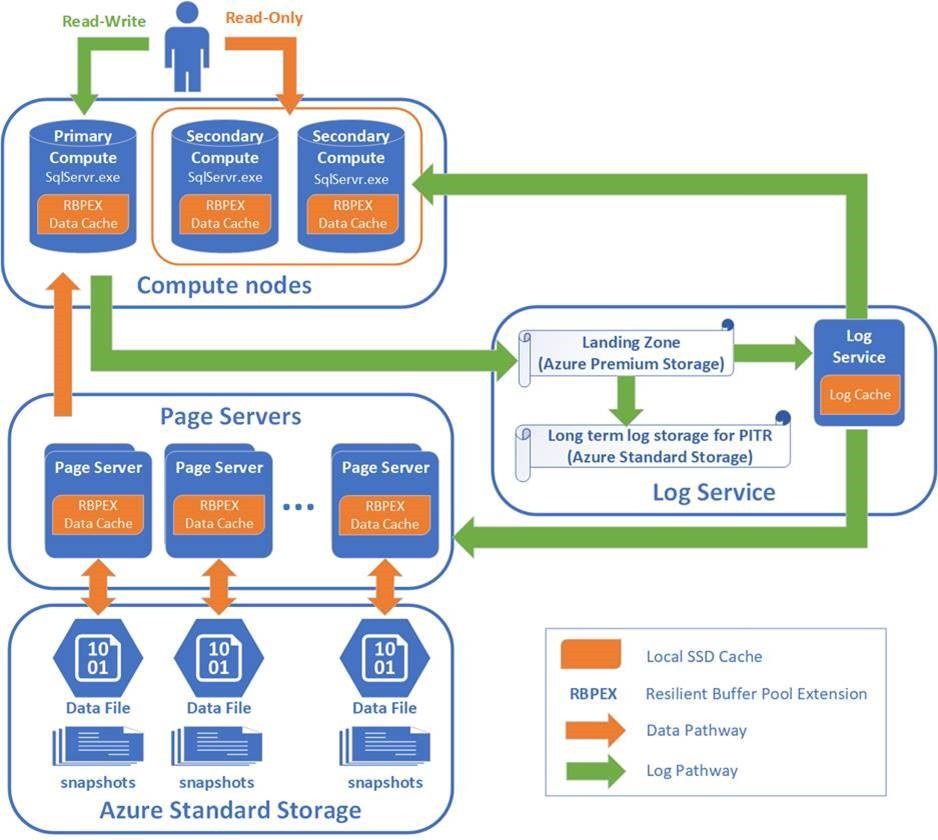
ストレージが根幹のサービスだけあって、仕組みスライドもストレージがメインとなっています。
バックエンドにデータストア層があって、そこをコンピューティングが参照する。
プライマリもセカンダリも同じデータストアを見るので、データ反映タイムラグがレプリケーションよりも断然抑え込まれています。
ここで掲載されています。
一番大きいのは80コアモデル。
Storage Typeがまだ、LOcal SSDとなっているのはご愛嬌。
Azure SQL Databaseが最大容量4GBで苦しんでた皆様が解放される日はもう間も無くです!
そこまで、なんとか生き延びましょう(^ ^)
MSSQL Tiger Teamが投稿したBlogを基に整理した内容です。
可容性グループはSQL Server 2012で初めてリリースされました。
可容性グループセカンダリレプリカの各データベースではトランザクションログのredoは一つのredoスレッドで制御していました。
このredoモデルは、serial redoと呼ばれていました。
SQL Server 2016で、redoモデルが強化され、redo操作を分けるためにデータベース毎に複数の並列redoワーカースレッドになりました。さらに各データベースは、ダーティページディスクフラッシュIOを管理する新しいヘルパーワーカースレッドがあります。
この新しいredoモデルは、parallel redoと呼ばれます。
新しいparallel redoは、SQL Server 2016から既定の設定で、小さいトランザクションが並列に大量に実行されるケースではredo性能の改善ができました。データの暗号化、データ圧縮の有功などのCPU負荷の高いトランザクションredo操作は、serial redoと比較してparallel redoの方が高いスループット(Redone Bytes/sec)が得られます。
さらに、間接的チェックポイントがparallel redoがヘルパーワーカースレッドにディスクIOや遅いディク用のIO waitを委任し、メインのredoスレッドがセカンダリレプリカでログレコードをより受信できるようにします。redo性能を向上させます。
しかし、parallel redoはマルチスレッドモデルでコストが高いです。
性能研究に基づくと、次のトランザクションワークロードまたはSQL設定が既定のparallel redo モデルより良い結果となります。
次の場合は、serial redoに切り替えた方がredoスループットがよくなります。
いくつか紹介されていますが、個人的に興味があるものをピックアップ。
SQL Serverの事例として紹介されていますが、Azure SQL Database のgeo replicationを使用してセカンダリデータベースを使用しているケースでも同様の問題が発生します。
P15を使っていると、ジオレプリケーションはparallel redoが採用されているので、ここで紹介されたことと同じ問題が発生するのです。
Application GatewayでLet’s Encrypt証明書を設定しようとして、はまりにはまったので対応方法をメモしておく。
今回は、Application GatewayにカスタムドメインのサブドメインをAzure DNSで割り当てて、DNS-01認証でLet’s Encrypt証明書を取得する。取得には、win-acmeを使用した。
Application GatewayのURL:yyy.xxx.example.com
Azure DNSのDNSゾーン:xxx.example.com
発行したい証明書: yyy.xxx.example.com
修正前
_dnsClient.RecordSets.CreateOrUpdate(_azureDnsOptions.ResourceGroupName,
url.RegistrableDomain,
url.SubDomain,
RecordType.TXT,
recordSetParams);修正後
_dnsClient.RecordSets.CreateOrUpdate(_azureDnsOptions.ResourceGroupName,
"xxx.example.com",//url.RegistrableDomain,
"_acme-challenge.yyy".//url.SubDomain,
RecordType.TXT,
recordSetParams);5. ビルドしたletencrypt.exeを起動する。
M: create new certificate with advanced optionsを選択
1: Manually input host names を選択
yyy.xxx.example.com を入力
1: [dns-01] Azure DNS を選択
Tenant Idを入力する。(Get-AzureRmSubscriptions)
Client Idを入力する。(Get-AzureRmADServicePrincipal|where DisplayName -EQ LetsEncrypt のApplication Id)
SecretはService Principalを作成するときに設定したパスワード
DNS Subscription IDは、xxx.example.comのDNSゾーンで表示されるもの
DNS Resource Groupは、xxx.example.comのDNSゾーンで表示されるもの
これで無事に証明書が発行される。
次のエラーが出るときは、「xxx.example.com」へのアクセス権を付与していることと、ソースコードを修正していることを確認してください。ソースコードを修正していないと、「example.com」DNSゾーンにレコードを作ろうとするので下記エラーが発生します。
The client ‘d38f55be-xxxx-xxxx-xxxx-xxxxx’ with object id ‘d38f55be-xxxx-xxxx-xxxx-xxxxx’ does not have authorization to perform action ‘Microsoft.Network/dnszones/TXT/delete’ over scope
Azure SQL Databaseの監査ログを見るとき、知らないと面食らうというか上手く使えなくてしょんぼりすることがあります。
ちょっとしたポイントを知っておくと幸せになれます。
監査ログをAzure ポータルで参照しようと思うと最終的にはクエリエディターを起動することになります。クエリエディターのログインに使用するアカウントは管理アカウントになります。
クエリエディタが起動すると次のようなクエリが書かれています。
SELECT TOP 100 event_time, server_instance_name, database_name, server_principal_name, client_ip, statement, succeeded, action_id, class_type, additional_information
FROM sys.fn_get_audit_file(‘https://xxxxxxx.blob.core.windows.net/sqldbauditlogs/xxxxxxxxx/xxxxxxxx/SqlDbAuditing_Audit/2018-08-29/04_00_49_057_2108.xel’, default, default)
WHERE (event_time <= ‘2018-08-29T04:00:51.022Z’)
/* additional WHERE clause conditions/filters can be added here */
ORDER BY event_time DESC
Blobファイルを読み込んで検索していますね。
ファイルが細かく分かれているので、ほかのファイルも対象にしたくなります。
ドキュメント読んでワイルドカードとか試したのですが、あまりちゃんと動かず、結局たどり着いた結論は、「前方一致」したものが対象になるでした。
例えば、Blobファイルの指定を、「
https://xxxxxxx.blob.core.windows.net/sqldbauditlogs/xxxxxxxxx/xxxxxxxx/SqlDbAuditing_Audit/2018-08-29/ 」とすると、8/29のものがすべて。「
https://xxxxxxx.blob.core.windows.net/sqldbauditlogs/xxxxxxxxx/xxxxxxxx/SqlDbAuditing_Audit/2018-08-2」とすると、20日~29日が対象となります。(たぶんねw
データ量が多いと検索にえげつない時間かかります。
自分が試した環境だと10分程度でも結果出るのに1分とかかかりました。
つらいですね。
もう少し素敵な検索方法は、SQL Server Management Studioを使うことです。
ポータルでやるのはあきらめて、ここの真ん中あたりに記載がある「SQL Server Management Studio (SSMS 17 以降) で [監査ファイルの統合] を使用します。」の手順にのっとるのがいい。
これを実行すると、Blobストレージのアクセス権APIキーを設定した後、取り込みたい範囲を指定して、ローカルにダウンロードし、SSMSでフィルタリングとかをして調査をします。
めっちゃいい!と言い切れない部分もあるのですが、Azure Portalよりは断然ましです。