元記事:Quest powers Spotlight Cloud with Azure
Quest の Spotlight は、昔からSQL Serverの性能モニタリングとチューニングをする際に使用するととても便利なツールとして知られてきました。その製品をSpotlight Cloudとして、Azure SQL Databaseの性能モニタリングに特化したものに進化して提供されています。
Spotlight Cloudは、Azure Cosmos DBとAzure Functionsを利用して開発しています。
Spotlight Cloudとして必須要件は以下のようなものでした。
- 収集した多くの様々な形式のデータをAzureベースのストレージに送信して保存できる。
データは、SQL Server DMVやOSのパフォーマンスカウンター、SQLプラン、その他の便利な情報などが含まれます。
収取するデータは、データによって、データフォーマットとサイズ(100バイト~数メガバイト)が多岐にわたります。
- Spotlight Cloudを使用する顧客が増えるのに合わせて、拡張し続けられて、秒間1200操作を受け付けます。
- SQL Serverの性能問題を素早く分析し診断するために、データの紹介と結果の取得を返します。
解決策
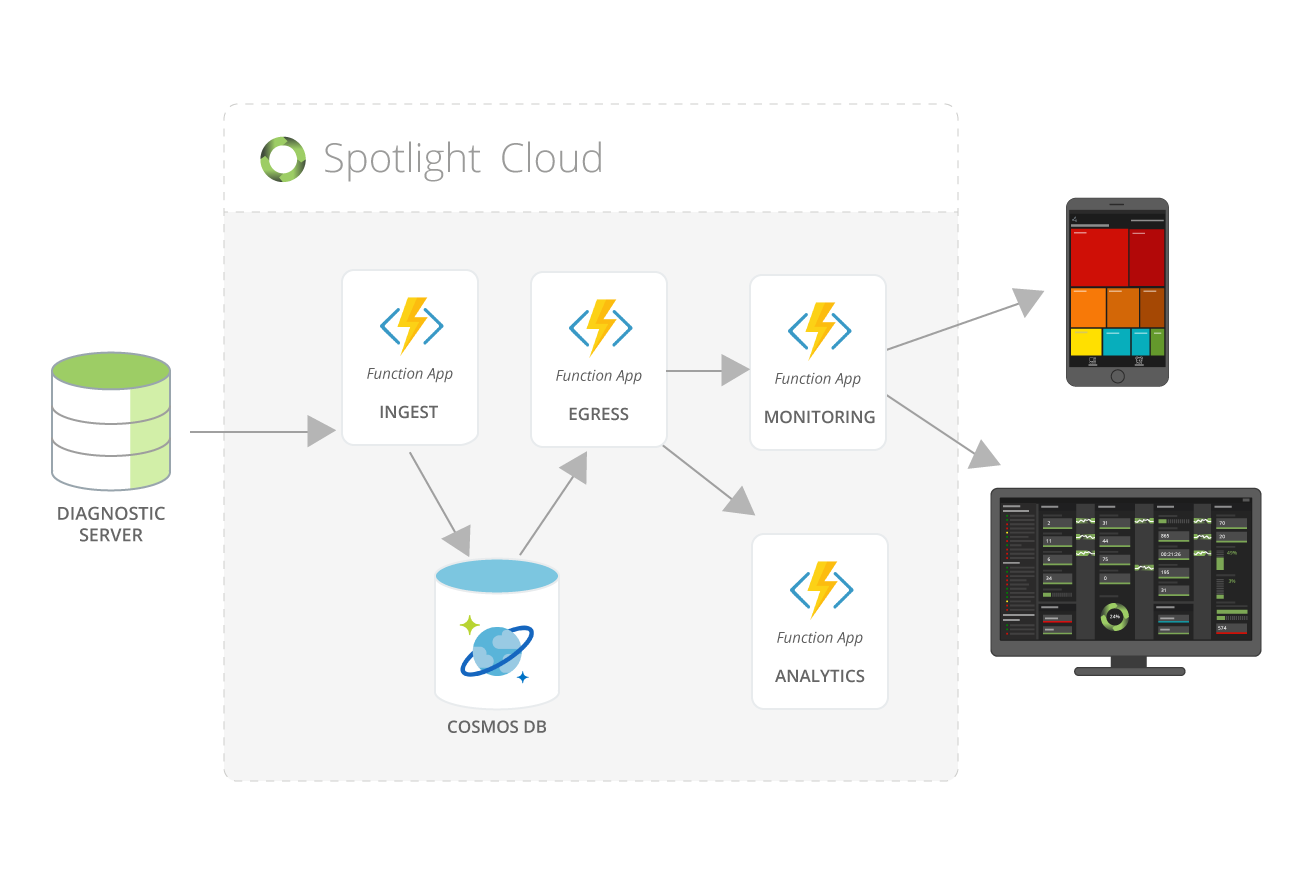
この図は、Spotlight Cloudのコア部分のデータフローです。図示していませんが、Event Hub、Application Insights、Key Vault、DNSなども利用しています。
Spotlight Cloudのコア部分は、Azure FunctionsとCosomos DBで構築しました。
この技術選択は、高い拡張性と性能を提供してくれます。
拡張性
Ingestアプリは、秒間1000以上の顧客モニタリングデータを処理します。
これを実現するために、Azure Functionの従量課金プランで自動的に100VMまで自動スケールアップさせます。
Azure Cosmos DBはSLAで保障されたリクエスト単位/秒(RU/s)で計測されるデータベースとコンテナーのスループットが保証されます。
見積もりをするためにReadとWriteのスループットを計測して予測しました。
性能
Azure Cosmos DBは、60ミリ秒以下でQuestアプリケーションのReadとWrite処理をします。
これは素早くSQL Serverのデータを分析しリアルタイムに診断を提供するのに役立ちます。
高可用性
Azure Cosmos DBは、2リージョン以上使用している場合、99.999%の高い可用性SLAを提供します。
フェイルオーバーが必要になったとき、Azure Cosmos DBは自動的にフェイルオーバーし、継続性を提供します。
簡単な操作で世界分散ができ、自動的に非同期にリージョン間のデータ同期ができます。
スループットを最大限利用するため、Questでは、書き込み専用の1つのリージョンと読み取り専用の1つのリージョンを使用しています。
結果、ユーザーの読み取り性能時間は書き込み量に影響を受けなくなりました。
柔軟なスキーマー
スキーマーとサイズが自由なJSONデータを扱います。
SQL Server DMVやOS性能カウンターなど様々なデータ源から様々なデータを受け取れます。
これはスキーマー管理やスキーマー修正の必要性から解放されます。
開発生産性
Azure Functionは、開発プロセスをスムーズにしました。
Cosmos DBのクエリ言語も簡単に使うことができました。
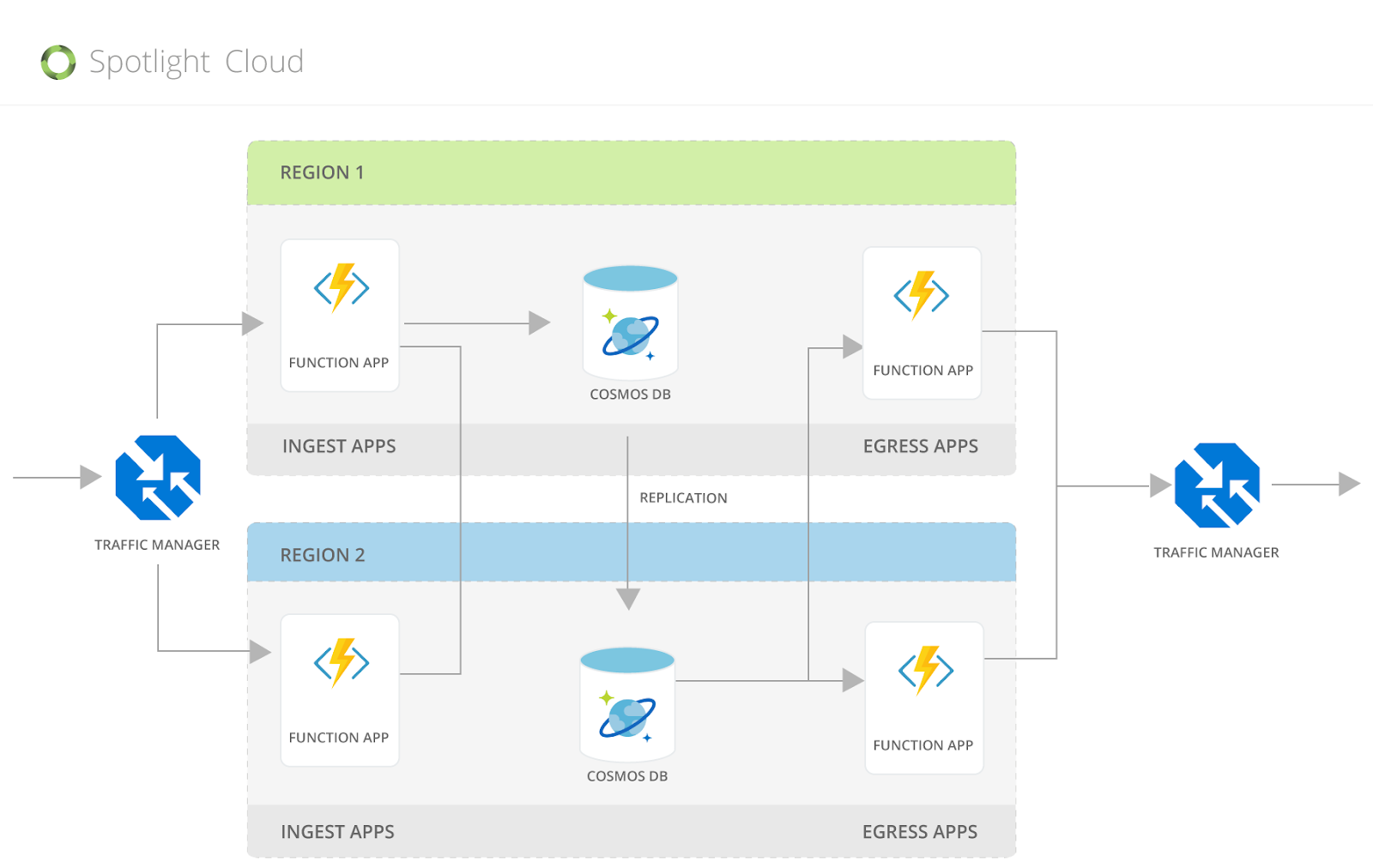
データは、Traffic Managerによって、Ingest Appに提供されます。
Ingest AppはCosmos DBの書き込みリージョンに書き込みます。Traffic Manager経由で、Azure Cosmos DB Readリージョンからデータを読み込んだEngress Appからデータが提供されます。
Questの学び
Azure Cosmos DBを効率的に使う方法について、Questは深く学びました。
- Azure Cosmos DBのプロビジョンニングスループットモデル(Ru/s)を理解する
Questはそれぞれの操作でコストを計測しました。秒間何操作で、合計どれぐらいのAzure Cosmos DBのスループットが必要なのかを算出します。
Azure Cosmos DBの費用は、ストレージとスループットに依存するので適切なRUSを選択する必要があります。
- 適切なパーティション戦略を選ぶ
パーティションキーを選択し、ストレージとリクエスト量が分散されるようにしました。
これはとても重要です。Azure Cosmos DBはデータを水平分散し、プロビジョニングされた総RUをデータのパーティション間で均等に分散させます。
開発段階で、いくつかのパーティションキーを試し、計測しました。
もしアンバランスなパーティションキーを選択すると、余分にRU/sが必要になってしまいます。
Questは、サーバーIDとデータ型を組み合わせた合成パーティションキーを選択しました。
これにより高い基数が得られ、データの均等な分散を得ることができました。
これは書き込みの多いワークロードには不可欠な対応です。
- Questの多い書き込み量のため、インデックスのポリシーと書き込み時のRUコストを調整することは良い性能を得るのに重要です。
インデックスポリシーを変更して、よく利用されるプロパティに明示的にインデックスを付け、残りを除外しました。
よく利用されるプロパティをドキュメント本文に2,3個入れ、残りのデータを1つのプロパティに格納しました。
- Questは書き込み量が多く、直近のデータがよく参照されるモデルです。
データを複数のコンテナーに分割し、新しいコンテナーは高いRUで定期的に作成(毎週~数か月)し、書き込みを受け付けます。
新しいコンテナーが容易で来たら、前のコンテナーはRUを縮小します。

