元記事:How Skype modernized its backend infrastructure using Azure Cosmos DB
Skypeは従来、SQL Serverをデータソースに使用して運営されてきました。
3か所のデータセンターにSQL Serverを分散して配置し、アプリケーション側のロジックで3か所にユーザーデータをパーティショニングしていました。
マイクロソフトに買収された後、SkypeはデータベースチームをMicrosoftに移し、データベースの管理を委譲しました。
そうして運用してきましたが、40憶ユーザーを支えるには、システム的な限界が来ていました。
デッドロックの発生や、スキーマー変更の難しさ、レコード量の多さによる性能劣化、独自パーティショニング技術の維持など技術負債がありました。
開発概要
Skypeは新しいアーキテクチャによるシステムに切り替えるため、2017年5月から開発を開始し、2017年10月までに開発を完了しました。
チームは、8人の開発者、1人のプログラムマネージャー、1人のマネージャーで構成していました。
移行後は、Cosmos DBには140TBのデータが含まれ、毎秒最大15000回の読み取りと6000回の書き込みを処理しています。
利用状況を監視して、RU使用量を必要に応じてスケールアップさせて割当量を自動で増やしています。
初期設計
チームは、Azure Cosmos DBの利用経験はなかったのですが、開発スピードを上げるのは容易でした。
物理的なインフラストラクチャを気にしなくていい、SQL構文とChange Feedの両方が組み込まれたスキーマーフリーのドキュメントデータベースを提供している、SLAが提供されているなどから迅速に開発できました。
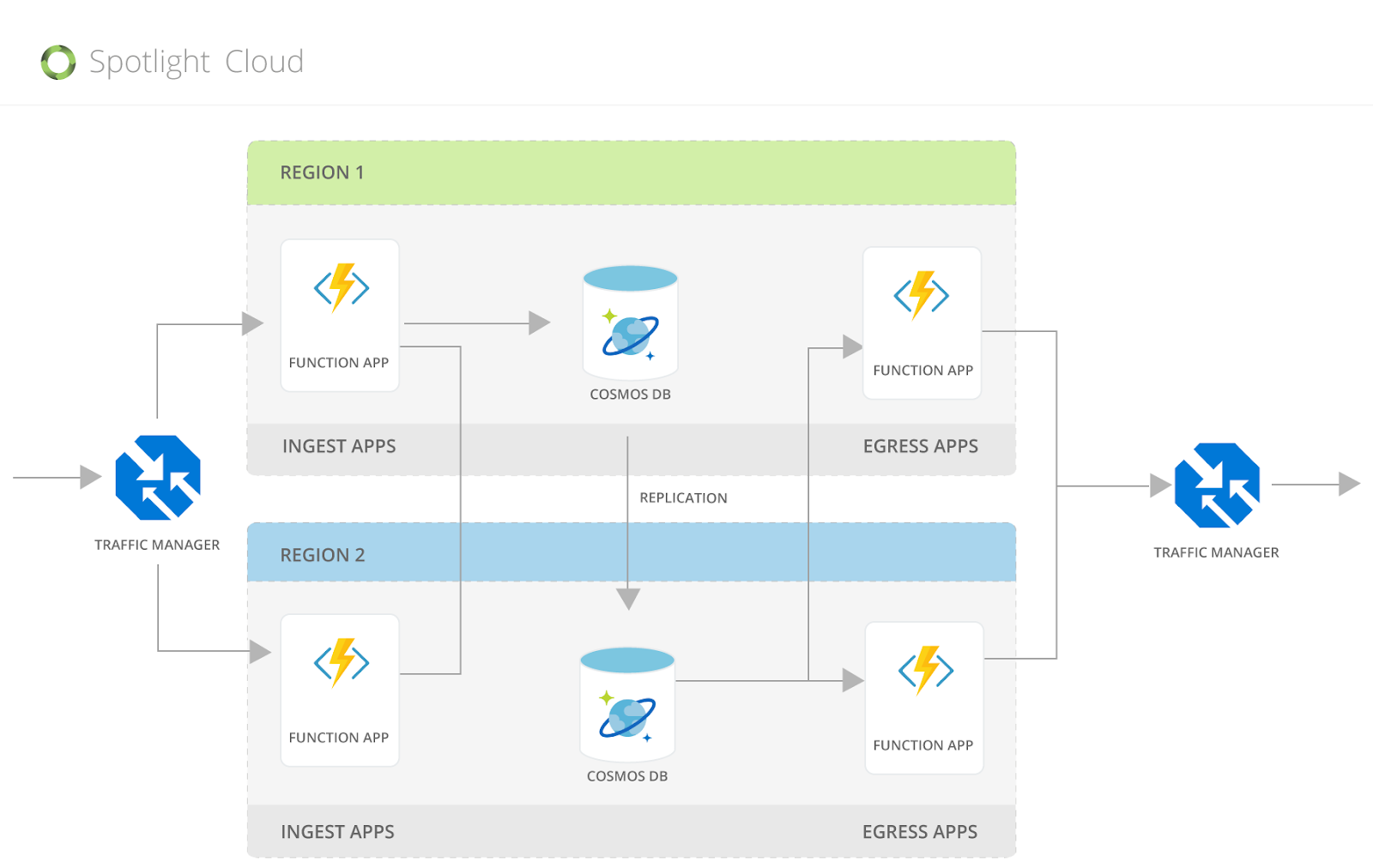
- 地理的冗長性:北米、ヨーロッパ、アジア太平洋の3リージョンに1つずつ配置することで、1秒未満でレスポンスを返すというSkypeのSLAを満たしました。
- 一貫性レベル:Cosmos DBが提供する5つの一貫性レベルからSession一貫性(読み込みは先祖返りしない、書き込み順序は保証される、書き込み処理したプロセスは書き込み後のデータが読める)を選択しました。
- パーティショニング:パーティションキーとしてUserIDを選択。各ユーザーのすべてのデータが同じ物理パーティションに存在するようになりました。
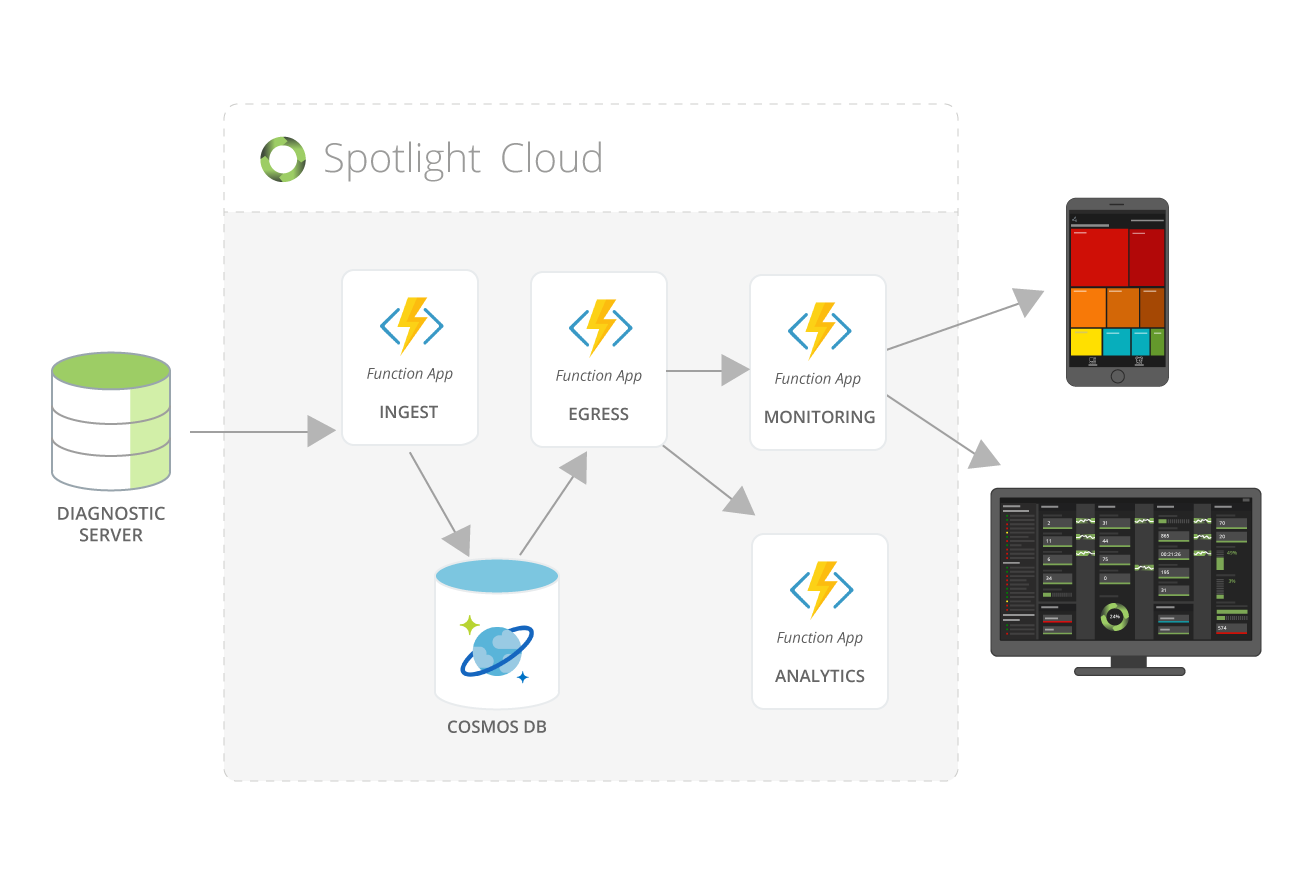
Change Feedに基づくイベント駆動型アーキテクチャ
Azure Cosmos DB のChange Feedに基づくマイクロサービスのイベント駆動型アーキテクチャを実装しました。
通常、イベント駆動型アーキテクチャでは、Kafka、Event Hubなどのイベントソースを利用しますが、Cosmos DBはChange Feedを組み込みで提供しているためアーキテクチャをシンプルにできます。
監査履歴のために、状態取得によるイベントソーシングパターンを実装しました。
ドメインで現在の状態のデータを保存する代わりに、このデザインパターンでは、データに対するすべての操作を変更された状態とともに保存していきます。
トランザクションデータの一貫性を提供し、保管対応ができる完全な監査証跡と履歴を維持します。
性能最適化のために読み込みと書き込みのパスとデータモデルの分離
コマンドとクエリの責任分離パターン(CQRS)を使用しました。
書き込みと読み込みのパスとインターフェイスとデータモデルを分離しました。
イベントの保存がWriteモデルで、何が発生して変わったのか、何を意図するのか、だれが実行したのかを提供する情報源です。
これらすべては各変更毎に一つのJSONドキュメントに保存されます。
読み取りモデルは、マテリアライズビューで小さなJSONドキュメントで参照に最適化されています。
詳細は、イベントソーシングとCQRSを参照してください。
独自のChange Feed処理
Azure Functionを使用してChange Feedをの処理を扱う代わりに、開発チームは、Azure Cosmos DB change feed processor Libraryを使用して、独自にChange Feedを処理する実装を開発することを選択しました。
Azure Cosmos DB change feed processor Libraryは、Azure Functionの内部的に使用されるコードと同じです。
これを使用することで開発者は、Change Feed処理を細かく制御できます。
キューに対する再試行の実装、配信不能イベントのサポート、詳細な監視などが可能になります。
このアプリは、仮想マシンPaaS v1モデルで動作しています。
学んだ教訓
- 性能向上のためにダイレクトモードを使用する
クライアントがAzure Cosomos DBに接続する方法はデフォルトのゲートウェイ接続モードからダイレクトモードに切り替えました。
クライアント側の待ち時間の短縮につながります。 - ストアドプロシージャーの作成と処理方法を学ぶ
トランザクションはストアドプロシージャーのみで対応しています。JavaScriptはデータベースと同じメモリスペースでホストされます。 - クエリの設計に注意を払う
クエリのはRUの消費という点で大きな影響を与えます。
可能な限り読み取りポイントドキュメントを使用したり、API毎にクエリを最適化しました。 - Azure Cosmos DB SDK 2.xを使用して接続を最適化する
クライアントSDKがパーティションをホストしている物理ノードとの接続を確立する必要があります。
Cosmos SDK 2.xで接続の多重化がサポートされ、SNATポートの枯渇問題の軽減に役立ちました。