今後、改善が入るとおもうので、あくまでも本日時点の考慮ポイントとなります。
1.新規にHyperscale環境を作成し利用する
現在、128GB以上を使用しているDTUモデルのAzure SQL Database からHyperscale環境に移行をしようとしていて、かつ少しでも性能をよくしたい場合の話になります。
128GB以上を使用しているデータベースから移行する場合は、新規にHyperscale環境を作成し、データをMigration Wizardなどクライアントツールを使用してデータを移行させて、アプリケーションの向き先を切り替える対応が最もHyperscale環境の性能が良くなります。
Azure Portal の設定から、モデルを切り替えた場合は少し性能的に不利になります。
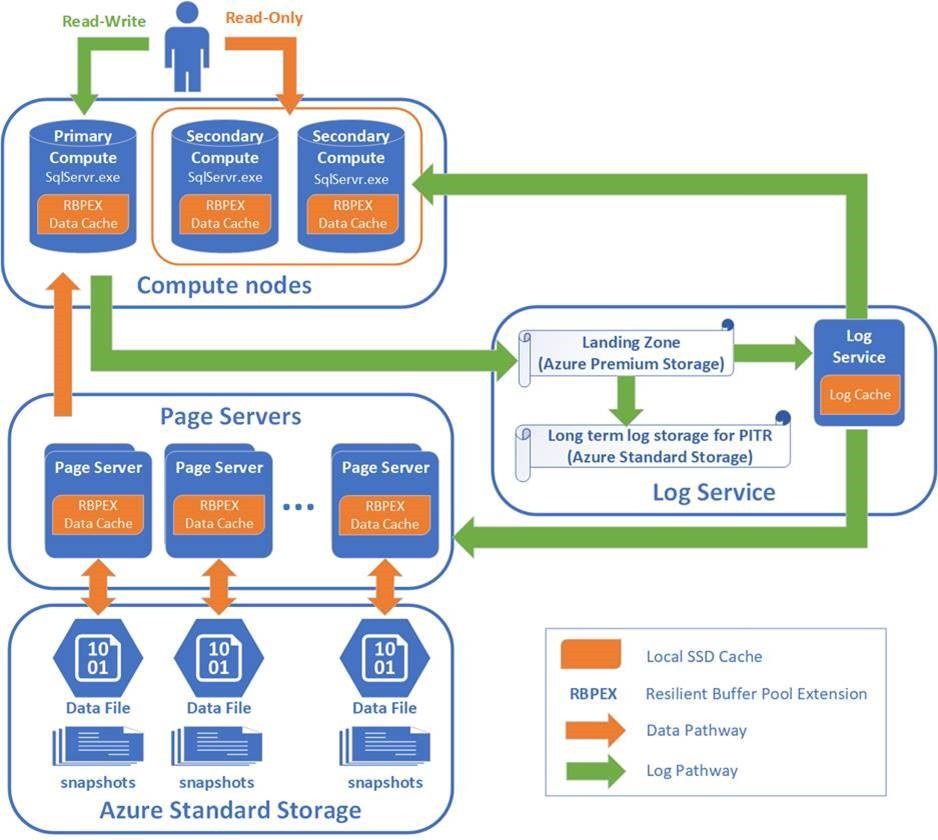
Azure SQL Database ではデータファイルのサイズが1TBと128GBの2種類が提供されています。
そして、128GBのデータファイルを使用したほうが、性能的にちょびっと有利になります。
128GB以上を使用しているデータベースから移行すると、データベースファイルは1TBが使用されてしまいます。
新規環境にデータを流し込むことで、128GBのデータファイルが選択され、追加されていくので性能的に有利になります。
現在のところ、データファイルサイズを明示的に選択はできないので、マイグレーションは新規にするのがよさそうです。
※性能影響なんであるの?どれぐらいあるの?は、きっとムッシュ案件。
2.CPUコア数の選択
P15 4000DTUのCPUコア数は通常32コアになっています。
その環境からHyperscaleに移行するなら、40コアでいいのかなと思うのですが、ちょっと事情が違うかもしれません。
ハイパースレッディングがらみで、DTUの32コアは、Hyperscaleの64コア相当になるかもしれません。
(これは、まだ検証中)
なので、4000DTUから移行するときには、80コアがよさそう。
なんとなく80コアを選ぶと、CPU使用率が2/3になったので、間違ってはなさそう?
3. DTUからHyperscaleへの移行時間
3TBぐらいあって、時々書き込みが発生するDTU P11からHyperscale 第4世代6コアに、Azure Portalから移行させました。
設定変更ボタンを押してから5時間程度かかって、最終処理、環境の切り替えで約8分ほどオフラインになった後、Hyperscaleに変更されました。
設定で対応する場合には、8分オフラインになることを見越して計画をしましょう。