特徴
SQL Serverと100%に近い互換性があり、ネイティブでVNETに対応しています。
オンプレからクラウドへの移行を容易にします。
PaaSと同じインフラで、全てのPaaSの機能(自動バッチ、バージョンアップ、バックアップ、高可用性)を提供します。
・オンプレミスのSQL Server 2005から最新バージョンまで互換性があリます。
(バックポートして互換性を持たせたので、SQL Server 2005以降全てのバックアップファイルをリストアできます)
・通常のSQL Serverのリストアに対応
・SQL Agent
・SQL Profiler
・ログシッピング
・トランザクションレプリケーション
・データベースをまたぐクエリ
・Database Mail
・Service Brocker
・SQL CLR
・SSIS(もうまもなく)
・99.99% SLA
・自動バックアップ
・ポイントタイムリストア

細かい情報
| プロパティ |
値 |
備考 |
| @@VERSION |
Microsoft SQL Azure (RTM) – 12.0.2000.8 2018-03-07 Copyright (C) 2018 Microsoft Corporation. |
SQL Databaseと同じ |
| SERVERPROPERTY (‘Edition’) |
SQL Azure |
SQL Databaseと同じ |
| SERVERPROPERTY(‘EngineEdition’) |
8 |
Managed Instance専用 |
| @@SERVERNAME, SERVERPROPERTY (‘ServerName’) |
フォーマット:..database.windows.net |
例:my-managed-instance.wcus17662feb9ce98.database.windows.net |
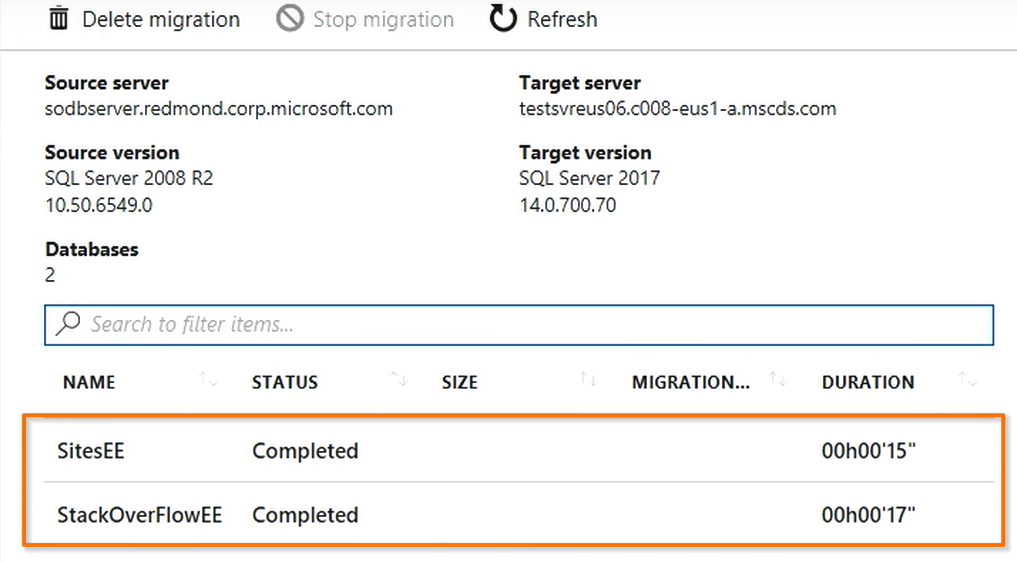
Azure Database Migration Service(preview)
SQL Server からAzure SQL Database Managed Instanceに簡単に移行できるように設計されています。
DocuSignもこれを使って移行しました。
サービス帯
Public Preview中は、General Purposeが提供されます。
基本的な可用性、共通的なIOレイテンシーようです。
・基本的な性能要求と可用性
・Azure Premium Storage(8TB)
・1インスタンス100DB
・8/16/24 vCore
・ストレージは32GB〜8TB
・500-7500IOPS/1データファイル
・1データベースのデータファイル数は複数
・ログファイルのデータファイルは1つ
・自動バックアップ
・可用性は、リモートストレージとAzure Service Fabric
・インスタンスとデータベースのモニタリングと計測
・自動パッチ
・監査ログ
・ポータル対応
メトリックス画面
監査ログと脅威分析
vCoreについて
vCore(Virtual Core)は、論理CPUで、2世代のハードウェアで提供されます。
・4世代:Intel E5-2673 v3 (Haswell) 2.4 GHz プロセッサー
・5世代:Intel E5-2673 v4 (Broadwell) 2.3 GHz プロセッサー
vCore、ストレージサイズのスケールアップダウンが必要に応じてできるようになっています。
(ポータルから設定できますが、ダウンタイムなどがあるのかは確認が必要ですねぇ)
データベースファルは全て分離されたPremiumストレージ上に配置されます。
オンプレミスとの違い
詳細な機能比較は、「こちら」
・可用性は組み込みで予め設定されています。Always On 可用性機能はSQL IaaS実装と同じ方法では公開されません。
・自動バックアップ、ポイントタイムリストア。バックアップチェインに影響与えない、コピー専用バックアップを出力できます。
・物理パスの指定ができません。Bulk insertはAzure Blobのみの対応です。
・Windows認証の代わりにAzure AD認証を提供します
・インメモリOLTPオブジェクトが含まれるXTPファイルグループとファイルは自動で管理します。
バックアップ
・Azure Blob認証
“`
CREATE CREDENTIAL [https://myacc.blob.core.windows.net/testcontainer]
WITH IDENTITY=’SHARED ACCESS SIGNATURE’
, SECRET = ‘sv=2014-02-14&sr=c&sig=GV0T9y%2B9%2F9%2FLEIipmuVee3jvYj4WpvBblo%3D&se=2019-06-01T00%2A%3AZ&sp=rwdl’;
“`
・コピー専用バックアップ
“`
BACKUP DATABASE tpcc2501
TO URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501.bak’
WITH COPY_ONLY
“`
・ストライプバックアップ
Blobは200GBのサイズ制限があります。次のようにしてファイルを分割してバックアップします。
“`
BACKUP DATABASE tpcc2501
TO URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-1.bak’,
URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-2.bak’,
URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-3.bak’,
URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-4.bak’
WITH COPY_ONLY
“`
・MAXTRANSFERSIZE
大きなデータベースの時には、MAXTRANSFERSIZE=4194304を指定するといいでしょう。
1ファイルあたり、48GBを超えないようにする。
COMPRESSIONで圧縮して帯域を節約します。
CHECKSUM or STATS = で正しくバックアップできたか確認してもいいでしょう。
“`
BACKUP DATABASE tpcc2501
TO URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-1.bak’,
URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-2.bak’,
URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-3.bak’,
URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501-4-4.bak’
WITH COPY_ONLY, MAXTRANSFERSIZE = 4194304, COMPRESSION
“`
価格
Preview版のお値段については、「ここ」に記載があります。
目的別に2種類のサービス帯が提供さえる予定なのですが、現時点では一般的なワークロード用のGeneral Purposeのみが提供されています。
「BASE RATE PRICE WITH AZURE HYBRID BENEFIT (% SAVINGS)」は、SQL Serverのライセンスを持っていて有効なSA権を持っている場合に、ライセンスをクラウドに持ち込んだ場合の価格です。
ですので、通常は「LICENSE INCLUDED PREVIEW PRICE」を選ぶことになります。
24vCoreを選択すると、東日本リージョンで375.44円/時間かかり、1日9,010円、1ヶ月279,327円かかります。
ストレージが最初の32GBがvCore代金に含まれていて、以後月1GB毎に7.73円かかり、最大8TBまでいけます。1TBで月7915円。
バックアップデータは月1GB毎に5.6円かかるので、月3000円。
IO100万毎に13.44円なので、50,000IOPSで、月58060円。
月間、高くても35万円あたりでしょうか。
プレビュー中はNW転送量に課金されません。
バックアップ費用の見積もり方
利用しているサーバーストレージサイズと同じ容量までは追加費用がかかりません。
それを超えると費用が加算されます。
100GBのデータベースの場合、100GBのバックアップまでは無料、110GBの場合は10GBが費用発生します。
2018/6/30まではバックアップ費用は発生しません。
提供されているリージョン
20リージョンで提供されています。
Canada Central
Canada East
Central US
East Asia
East US
East US 2
Japan East
Korea Central
Korea South
North Central US
North Europe
South Central US
South India
Southeast Asia
UK South
West Central US
West Europe
West India
West US
West US 2