セッション概要
Developer Camp 2012 Japan Fall
Day1 2012年10月4日(木)16:40~17:40
Microsoft Corporation
Azure Application Platform Team
Software Development Engineer in Test
河野通宗
Togetter:Inside Windows Azure Web Sites by @superriver
セッション資料
Windows Azure Web サイト (コードネーム Antares) の内部の仕組みについて詳しくお話します。Web サイトのロール構成、プロビジョニング時の動作をはじめ、高可用性とスケーラビリティを提供するメカニズムについて、開発チーム中唯一の日本人エンジニアが開発途中のエピソードも交えてお伝えします。エバンジェリストも知らない話が聞けるかも知れません。
河野通宗さん
Azure Webサイトを作っている人。
SDET(Test Developer:テストコードを毎日書いて触ってきゃっはーと楽しんでいる)人で
Twitter:superriver(帝国兵と俗に呼称されている)
チーム
Azure Webサイトのコードネーム:アンタレス(Antares)
アンタレスチームは40人(Dev/Test/PM)。
スコット・ガスリー配下のチームメンバーは2~300人。
AAPT(Azure Application Platform)チームで、Websites以外にも幾つか存在する。
部屋の看板?  スコット・ガスリー配下のチームロゴなんだって。
スコット・ガスリー配下のチームロゴなんだって。 
Windwos Azure Websiteとは
Strat Simple
- 数クリックで1つのWebサイトをクラウド上に作成できる。
- ギャラリーから作成できるサイトは幾つかメジャーなOSSに対応している。
メジャーなOSSの定義は、マイクロソフトが提供している簡単にパッケージをインストールできるツールであるWebPI(Web Plat form Installer)のダウンロード数が多いところから結構選んでいる。(Websitesに入れたいOSSがある場合は、WebPIでせっせとダウンロードしたら対応するかも) - データベースを提供している。
MySQLは20MBまで設定不要で最初から使えるようになっている。 - お試しで10サイトまで無料で使えるようになっている。
Go Live
- 皆さんが使用しているリポジトリや開発環境をできるだけ受け入れたいということで、当初からGitとTFSはサポートしようと話していた。FTPは技術的に厄介な部分がありましたが、何とか解決しました。
Rapid Scale
- クラウドの特徴といわれるスケーリングがとても簡単である。
スケールアウトはインスタンスを簡単に増やせる。トラフィックが多いときにインスタンスを増やすことで簡単に対応できる。
スケールアップは、一つのインスタンスがメモリが足りない、サイズが足りないなどの場合に柔軟に変更できる。
 宣伝文句で、ASP.NET、MVC、Python、PHPをサポートとなっている。
宣伝文句で、ASP.NET、MVC、Python、PHPをサポートとなっている。
Rubyはサポートしないのかという話ですが、クラウドサービスの方では使えるなっていますが、Websitesの方でも使える。
開発動機
昔、大きくチームが2つありました。
河野さんは元々ファンダメンタルよりのAzureチームにいた。もっとデプロイの手続きを簡単にしたいと考える人がファンダメンタルなチームにいっぱいいました。
具体的に改善したいと思ったことがあって、ミニプロジェクトが立ち上がった。
- デプロイ時間
- スケール
スケールが簡単だとは言っていたがスケールを変えようと思うとクラウドサービスではコンフィグレーションを書き換えないといけなくて言うほど簡単ではなかった。 - 既存資産が再利用しづらい
クラウドサービスは、WebロールやWorkerロールなどで基本従来のWindowsの開発モデルとはだいぶ違うところがあった。既存資産の再活用がしずらかった。
一方で、IIS 6やIIS 7を開発し続けていたチームがありました。
IISの基本機能として元々マルチテナントの機能を持っていたが、それなりの問題点もあった。
問題点があり、改善しようとプロジェクトが走っていました。
- ストレージの保守
100ホストとか、たくさんのホストをテナントした場合にファイルの容量を増やすのが容易ではなかった。 - スケーリング困難
スケーリングするのに、メモリを増やしたりHDDを増やすのが容易ではない。ダウンタイムが発生する。 - 複雑な初期設定
この2つのプロジェクトが社内のデモの場か何かで、お互いの存在を認識し、似たようなことやってるなら一緒にやろうよっとなり、プロジェクト・アンタレスが1年半ほど前に始まった。
 Antares開発プロジェクトの原則
Antares開発プロジェクトの原則

どこかに明文化されているわけじゃないけど、開発の経緯をみてきて河野さんなりにまとめてみた。
- セキュリティの確保されたマルチテナント環境
マルチのテナント環境でセキュリティとかプロテクションは絶対に提供しないといけない。普通のIISではアプリケーションプールだけですが、もっとセキュリティを確保したホスティング環境を提供する必要がある。 - 単一ビルドでクラウドとオンプレミス双方をサポート
Websitesはプログラム自体は、単一のビルドでオンプレミスでも動くようになっていて、また動くように作った。msiのパッケージになっていてWindows Serverに普通にインストールできる。大きな制約でAzure特有の機能を一切使用できなかった。Service Busとか使わない縛りの上でやっている。 - 可用性重視(ダウンタイムをゼロに近づける)
クラウドと言っても、ハードウェアとソフトウェアの上で起きることは何でも起きるのがクラウド。だからできるだけダウンタイムを減らして、アベイラビリティを高める。これは重視して、投資をしている。 - パフォーマンス低下をできるだけ抑える
いろいろやろうとすると当然ながらパフォーマンスが低下する。その低下をできるだけ抑えるように開発した。
全体構成
次の図が全体構成。ピンクの部分はAzure自体のインフラで、この部分はAzure Websaitesチームは触れることができない。Azureインフラの上にWebsitesを構築している。
赤色の部分がAzure Websitesの部分で、大きく2つに分かれている。
1つが、Websites master API endpoint。Azureのインフラと直接通信して、サイトを作成したり、削除したりする。メインのコントローラー部分。
そして、Stamp。実際にサイトを作成した時に、サイトが格納される場所となっている。
Azure Websitesは、クラウドサービスとして実装されていて、Azureの上に作られている。

Stampの部分が世界各地のデータセンターに展開されていて、今後増やしていきたいと思っている。
アジアにも1つStampを置く予定となっている。今、設定をしたりする。
サイト新規作成
サイトを作成するときの挙動についての説明。
- ポータルに対してsite1を作成する指令を出す。
- 指令を出すと、site1作成命令のクエリがMasterに届く。
- site1作成の指令をした際に指定したリージョンに対応したStampのAPIに対してリクエストする。
- Stampにサイトを作成。
- 作成できたら、StampのAPIからAzureのインフラ(DNSサーバ)に対して、site1はStamp2にあるっと登録する。
Azure Webサイトの外側からもsite1のIPがわかるようになる。
- 無事成功したら、リターンコードが返る。



サイト呼び出し
Webブラウザ開く際の挙動についての説明。
- クライアントからAzureのDNSサーバーにsite1のIP問い合わせ。site1は、Stamp2にあると知っているので、Stamp2のロードバランサーのエンドポイントのIPを返す。
- クライアントは、Stamp2のロードバランサーのエンドポイントのIPにパケットを飛ばす。
- Stamp2にも負荷分散のために複数あるエンドポイントのどれかに対して、ロードバランサーはリクエストを投げる。

- stampにアクセスが来ると複数あるFrontendにランダムにパケットが飛ぶ。
- Frontendは、どのWebWorkerにパケットを投げていいのかを知らないので、Runtimeデータベースと通信し、ストアドプロシージャが一番負荷の少ないWebWorkerを選択し、Frontendに返す。
- Frontendは、選ばれたWebWorkerの情報を内部のキャッシュに格納する。Frontendは選ばれたWebWorkerにパケットを転送する。

- WebWorkerに対してリクエストが投げられたが、この段階ではWebWorkerにはコンテンツが何もない。

WebWorkerはRuntimeデータベースと通信し動的にサイトを構築する。具体的にはアプリケーションコンフィグを作成する。WebWorkerはsite1の実態を作り出す。
- サイトの中身は、File Serverを経由してVHDファイルを持ってくる。サイトのコンテンツによっては、サイトごとにデータベースを持っているので、SQLにデータを発行してデータベースを作成する。
- サイトが作成されたのでFrontendにHtml、XMLのフォーマットで返す。






サイト呼び出し(Hot)
前の手順は複雑で時間がかかる。すでに一度WebWorkerの上にサイトが作成された場合について説明する。
- AzureのロードバランサーからFrontendにリクエストが飛ぶ。
- Frontendは、どのWebWorkerにsite1が乗っているかを知っているので、Runtimeのデータベースにアクセスせずに直接WebWorkerにパケットを投げる。
- WebWorkerも情報を持っているので、データベースを参照せずFileServerを見に行く。変更がなければFile ServerにキャッシュされているのでVHDにアクセスしにいきません。
blobsは容量は大きいがローカルディスクに比べて遅いので、キャッシュしてアクセスを減らすようにしている。

この仕組みがあるだけで、エクストララージでホストされているWebWorker1つで、1000以上のサイトを軽くホスティングすることができる。DWSがこのサービスの肝になっている。
データベースがパフォーマンスのボトルネックとなるので、サイトがすでに出来上がっている場合は、データベースへのアクセスを抑えるように実装されている。Runtimeのデータベースがダウンするとシステム全体がダウンしてしまうので、システムの弱いところとなっている。
もっと厄介なのがサイトと直接通信するSite DB。こちらはコンテンツ(CMS)次第なので手出しができない。CMSによっては秒間数百のトランザクションを発行させるので、1つのWebWorkerにいくつもホストされるとスロットリングを起こしてしまい、ほかのサイトまでアクセスできなくなってしまう。
問題解決が困難なのでSQLのアクセスだけは、移し替えてある。
※行間を勝手に補足して想像してみると……。
同一のWebWorkerから、SQL Databaseに大量にアクセスすると、SQL Detabaseのスロットリングサービスの対象になってしまう。
根本解決が困難なので、SQL Databaseにアクセスするサイトは別のWebWorkerに載せ替えて、高速に動作するようにしている。高速に動作すればSQLの問い合わせ時間が短くなるのでスロットリングサービスの対象になりにくい……ってことかな?
じゃ、Dos Guardの対象にもなっちゃったりするのかな?さすがに無いか……。
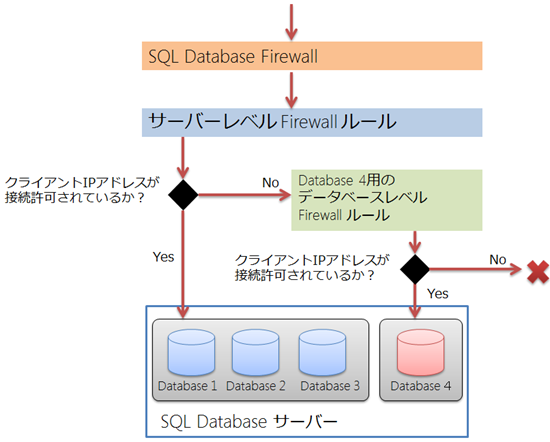
Stampの内部構造
Stampの内部構造は、次の要素で構成されている。

| API endpoint | Stamp内のAPIエンドポイントがStamp内のサイト作成などをつかさどっている。 |
| Frontend | IIS ARR上に実装されたロードバランサー |
| WebWorker | WebWorkerのインスタンスの上でサイトのコンテンツが読み込まれ動作している。シェアとかリザーブなどいくつかある種類は、WebWorkerの種類を指している。 |
| Runtime DB | SQL Databaseには、Runtimeの情報を保存している。 |
| Publish endpoint | WebDeployとかFTPなどの外からのリクエストを受け取るエンドポイント。FTPは、データのパスとコントロールのパスと2つセッションをはるが、Azureのロードバランサーはラウンドロビンでしか動かないので、Publish Endpointのインスタンスが複数あると分離されてしまってうまく動かないことがあるので、Publish endpointはAzure内ではあるがIPが固定されている。 |
| File Server | VHD Blobsに対してproxyの役割を果たすインスタンス。 |
上の図では、赤い四角1つしか書いてないところがあるが、全部複数のインスタンスを使用している。赤い四角を全部足して、1つのStampごとに1000インスタンスぐらい動作していて、今全部で5000インスタンスぐらい動いている。
ストレージ
コンテンツは、BlobのVHD上に格納されている。
File Serverは、VHDをドライブとしてマウントしている。File Serverは全部のVHDをマウントしている。File Serverには、必ずスペアの空いているスタンバイ用のFile Serverを用意している。 
File Serverに障害が発生したら、スペアのFile Severが切り離されたVHDをマウントしてダウンタイムを少なくしている。現在は切り替えに30秒ほどかかるので、短くしたいと考えている。 
現在のAzureドライブの仕様上限である1TBのVHDをたくさん保持している。1TBのVHDファイルを1つのStorageに100個までしか保存できないので、全部で100TBしかない。サブスクリプション辺りの容量が1GBなので、10万人程度しかホストできない。
なので、たくさんグループ化して使用するようにしている。これで無制限の容量を使用できるようになる。 
リージョンとサイト
「East USしか選べない」
「West USしか選べない」と言う質問がある。
一番最初にサイトを作成するときは、3~4か所から選べたが、一度選んでしまうと以後は、そのリージョンにしか作成できないようになっている。
サブスクリプションが課金単位。Websitesの中に、Webspaceという概念があり、ユーザー割り当て単位となっている。1つのサブスクリプションには1つのWebspaceという制約となっており、1つのWebspaceの中に最大10個までのWebsiteを作成できる。(これは実装上の問題なので、将来的には変更する可能性が高い。)

Websitesはいろんなことができる
WEBMARIXをクリックすると自動的にPublish設定ファイルをダウンロードしてきて、サイトを発行できる。

空っぽのサイトを作成。 
App_Codeというディレクトリを作成して、クラスを作成する。クラスを作成するとPublishした先で自動的にコンパイルして実行されるので便利。

リファレンスを追加。

クラスに追記。

スタートしていないので修正。

もっかい修正。

Defaultに記載。


デバッグするために、詳細エラー表示のためcustomErrosをoffに変更。

最後は、デバッグ過程であれやこれやとなったのでファイル名を変更して無事完了。


こんな感じで、プロセスを実行することもできる。
system32も見える。
他のサイトのコンテンツとかクラウドサービスは見えないようになっていたり、ローカルでWebsocketsを開いたり、セキュリティホールになりそうなものはプロテクションしている。
その範囲を除いて、いろいろできる。
notepadとか起動すると返ってこなくなってしまうので注意が必要。
監視系
独自の監視を作りこんでいる。
Azureがモニタリングのインフラを提供しているので、それを採用している。
各コンポーネントに対して、Azureインフラでモニタリングしている。
さらにAzureのロードバランサー経由で、外側からFrontendやPublisherに対してデプロイしたりアクセスしたりして正常に動作しているかを確認している。
全世界にインスタンスを置いて相互に死活監視をしてくれるゴメスというマイクロソフト外部のサービスを活用して死活監視をしている。

Failすると大量のメールが…。多いと一日1000通とかくる。
//マイクロソフトも開発者側への通知はメールなんだなぁ……。

開発プロセス
アジャイル開発で、1つのスプリントは3週間から長くても6週間。
バックログからフィーチャ洗い出しして、優先順位つけて実装するフィーチャを決定する。
スクラムは毎日短いミーティングをして情報共有している。
進捗を細かく確認しながら進める。
最初は30人全員でやっていたが、今はフィーチャごとに細かくチームを分けてスクラムを実施している。

テスト
以下のテストをすべて自動化していて、河野さんテスターチームは、テスト用コードを書くお仕事。自動化するメリットは、一度動いてしまえば以後は自動的にテストできる。
- 機能テスト
- End-to-endシナリオテスト
- ストレステスト
- パフォーマンステスト
- 可用性テスト
- セキュリティテスト
- アップグレードテスト
- アプリケーション互換性テスト
テストフレームワークは、(TFS便利だなぁ使おうかなと思った)作るのが好きなので、基本全部自分たちで作ってしまう。当然、ほかのチームが開発したもので使用できるものは使用する。再利用しやすいテストコードを書いている。
アップグレード
Azure固有の機能を使用しないという原則があるので、次のようなアップグレードとなっている。
- VIP swap不使用
- ダウンタイム ゼロ
- データベースのフリーズなし
アップグレードには注力していて、完璧と言えるまでは決してアップグレードを実施しない。サービスがダウンしないように注力している。
まとめ
クラウドとは?
クラウドとは何かを定義していません。
ユーザー含めて、みんなで使っていくものだと思う。
どんどん使ってフィードバックください。フィードバックに飢えています。
面白い使い方を教えてください。
教えてもらえると、チーム側のインプットになる。
クラウドは生もの。