Apache Hadoop on Windows Azureの操作例 その1
Apache Hadoop on Windows Azure CTPのアカウントを申込すれば、この情報を使用して新しいクラスタを作成することができます。もしHdoop on Azure CTPについて詳細を知りたい場合は、このBlog記事を参照してください。
コンテンツ
- 新しいHadoop ジョブ用のWindows Azureクラスタの作成
- サンプルの展開(Pi Estimator Hadoopジョブの作成)
- Word Count Hdoopジョブ作成と注意点
- MapReduceジョブとHDFS管理のためHadoopノードへリモートログイン
新しいHadoop ジョブ用のWindows Azureクラスタの作成
Hadoop on Azure CTPに接続し、Windows Liveアカウントでhttp://www.hadooponazure.comにログインします。
次の情報を入力する必要があります。
- Step1 DNS名
- Step2 クラスタサイズの選択
- Step3 クラスタにログインするためのユーザ名とパスワードの入力
- Step4 クラスタの要求

上記情報を入力し送信すると、クラスタとノードの作成が次の図のように始まります。

4つのクラスタを持つスモールサイズのクラスタを選択したので、(4ワーカーノードと1つのヘッドノードで)合計5ノードになります。ノードの作成状況は、次のように表示されます。

さらに・・・

クラスタは新しいHadoopジョブを作成する準備が整うと、次のような表示になります。

サンプルの展開(Pi Estimator Hadoopジョブの作成)
Windows Azure上にクラスタを作成すると、いくつかのサンプルがあらかじめ用意されています。サンプルを使用するために、「Sample」を選択します。

Hadoopサンプルで、「Pi Estimator」を選択します。

「Pi Estimator」のサンプル詳細が表示されます。詳細と説明を読んだ後、ボタンをクリックして、クラスタにジョブをデプロイすることができます。

新しいジョブウィンドウが開き、Hdoopジョブで使用するパラメータの追加と確認をします。パラメータを確認したら、「Execute Job」をクリックします。

Hadoopジョブが開始され、次のような通知が表示されます。

ジョブが完了すると、次のように結果が表示されます。
Pi Example
•••••
Job Info
Status: Completed Sucessfully
Type: jar
Start time: 12/29/2011 6:21:49 AM
End time: 12/29/2011 6:22:56 AM
Exit code: 0Command
call hadoop.cmd jar hadoop-examples-0.20.203.1-SNAPSHOT.jar pi 16 10000000Output (stdout)
Number of Maps = 16
Samples per Map = 10000000
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10
Wrote input for Map #11
Wrote input for Map #12
Wrote input for Map #13
Wrote input for Map #14
Wrote input for Map #15
Starting Job
Job Finished in 63.639 seconds
Estimated value of Pi is 3.14159155000000000000
Errors (stderr)11/12/29 06:21:53 INFO mapred.JobClient: Running job: job_201112290558_0001
11/12/29 06:21:54 INFO mapred.JobClient: map 0% reduce 0%
11/12/29 06:22:20 INFO mapred.JobClient: map 12% reduce 0%
11/12/29 06:22:23 INFO mapred.JobClient: map 50% reduce 0%
11/12/29 06:22:32 INFO mapred.JobClient: map 62% reduce 0%
11/12/29 06:22:35 INFO mapred.JobClient: map 100% reduce 0%
11/12/29 06:22:38 INFO mapred.JobClient: map 100% reduce 16%
11/12/29 06:22:44 INFO mapred.JobClient: map 100% reduce 100%
11/12/29 06:22:55 INFO mapred.JobClient: Job complete: job_201112290558_0001
11/12/29 06:22:55 INFO mapred.JobClient: Counters: 27
11/12/29 06:22:55 INFO mapred.JobClient: Job Counters
11/12/29 06:22:55 INFO mapred.JobClient: Launched reduce tasks=1
11/12/29 06:22:55 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=189402
11/12/29 06:22:55 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
11/12/29 06:22:55 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
11/12/29 06:22:55 INFO mapred.JobClient: Rack-local map tasks=1
11/12/29 06:22:55 INFO mapred.JobClient: Launched map tasks=16
11/12/29 06:22:55 INFO mapred.JobClient: Data-local map tasks=15
11/12/29 06:22:55 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=22906
11/12/29 06:22:55 INFO mapred.JobClient: File Input Format Counters
11/12/29 06:22:55 INFO mapred.JobClient: Bytes Read=1888
11/12/29 06:22:55 INFO mapred.JobClient: File Output Format Counters
11/12/29 06:22:55 INFO mapred.JobClient: Bytes Written=97
11/12/29 06:22:55 INFO mapred.JobClient: FileSystemCounters
11/12/29 06:22:55 INFO mapred.JobClient: FILE_BYTES_READ=2958
11/12/29 06:22:55 INFO mapred.JobClient: HDFS_BYTES_READ=3910
11/12/29 06:22:55 INFO mapred.JobClient: FILE_BYTES_WRITTEN=371261
11/12/29 06:22:55 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=215
11/12/29 06:22:55 INFO mapred.JobClient: Map-Reduce Framework
11/12/29 06:22:55 INFO mapred.JobClient: Map output materialized bytes=448
11/12/29 06:22:55 INFO mapred.JobClient: Map input records=16
11/12/29 06:22:55 INFO mapred.JobClient: Reduce shuffle bytes=448
11/12/29 06:22:55 INFO mapred.JobClient: Spilled Records=64
11/12/29 06:22:55 INFO mapred.JobClient: Map output bytes=288
11/12/29 06:22:55 INFO mapred.JobClient: Map input bytes=384
11/12/29 06:22:55 INFO mapred.JobClient: Combine input records=0
11/12/29 06:22:55 INFO mapred.JobClient: SPLIT_RAW_BYTES=2022
11/12/29 06:22:55 INFO mapred.JobClient: Reduce input records=32
11/12/29 06:22:55 INFO mapred.JobClient: Reduce input groups=32
11/12/29 06:22:55 INFO mapred.JobClient: Combine output records=0
11/12/29 06:22:55 INFO mapred.JobClient: Reduce output records=0
11/12/29 06:22:55 INFO mapred.JobClient: Map output records=32
戻るために矢印ボタンをクリックし、次のようにジョブ数と履歴が表示されます。

Word Count Hdoopジョブ作成と注意点
この例では、理解しやすさを優先するため、いくつかの意図的なエラーを残しつつ新しいHadoopジョブを開始します。Sampleにアクセスし、Wordcountサンプルジョブをクラスタにデプロイします。全てのパラメーターを確認し、次のようにジョブを開始します。

補足:次の二つの理由でエラーになります
- まだクラスタにdavinci.txtをアップロードしていない
- 誤ったパラメーターを設定している
ジョブが開始すると、すぐにこのエラーが発生します。

次のようなクラス名を見ることができ、このクラス名が誤っているためエラーになります。正しいパラメーター「wordcount」に修正して、ジョブを再起動します。
すると、次のような別のエラーが発生します。

この問題を解決するために、クラスタにファイル名「davinci.txt」のテキストファイルをアップロードします(この手順についての詳細な情報は、Wordcountサンプルページを参照してください)。
ファイルをアップロードするため、対話形式のJavaScriptコンソールを使用します。

対話形式のJavaScriptコンソールが開いたら、ローカルマシーンからテキストファイルを選択するために、fs.put()コマンドを使用し、クラスタのHDFSファイルシステムのフォルダーにアップロードできます。

ファイルアップロードが完了したら、次のような結果メッセージが返ってきます。

再度、ジョブを実行すると、おそらく次のような結果が表示されます。この問題を解決するために、2つ目のパラメータで、新しいアウトプットディレクトリ名を通す必要があります。
WordCount Example
Job Info
Status: Completed Successfully
Type: jar
Start time: 12/29/2011 5:33:00 PM
End time: 12/29/2011 5:33:58 PM
Exit code: 0Command
call hadoop.cmd jar hadoop-examples-0.20.203.1-SNAPSHOT.jar wordcount /example/data/davinci.txt DaVinciAllTopWords
Output (stdout)
Errors (stderr)
11/12/29 17:33:02 INFO input.FileInputFormat: Total input paths to process : 1
11/12/29 17:33:03 INFO mapred.JobClient: Running job: job_201112290558_0003
11/12/29 17:33:04 INFO mapred.JobClient: map 0% reduce 0%
11/12/29 17:33:29 INFO mapred.JobClient: map 100% reduce 0%
11/12/29 17:33:47 INFO mapred.JobClient: map 100% reduce 100%
11/12/29 17:33:58 INFO mapred.JobClient: Job complete: job_201112290558_0003
11/12/29 17:33:58 INFO mapred.JobClient: Counters: 25
11/12/29 17:33:58 INFO mapred.JobClient: Job Counters
11/12/29 17:33:58 INFO mapred.JobClient: Launched reduce tasks=1
11/12/29 17:33:58 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=29185
11/12/29 17:33:58 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
11/12/29 17:33:58 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
11/12/29 17:33:58 INFO mapred.JobClient: Rack-local map tasks=1
11/12/29 17:33:58 INFO mapred.JobClient: Launched map tasks=1
11/12/29 17:33:58 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=15671
11/12/29 17:33:58 INFO mapred.JobClient: File Output Format Counters
11/12/29 17:33:58 INFO mapred.JobClient: Bytes Written=337623
11/12/29 17:33:58 INFO mapred.JobClient: FileSystemCounters
11/12/29 17:33:58 INFO mapred.JobClient: FILE_BYTES_READ=467151
11/12/29 17:33:58 INFO mapred.JobClient: HDFS_BYTES_READ=1427899
11/12/29 17:33:58 INFO mapred.JobClient: FILE_BYTES_WRITTEN=977063
11/12/29 17:33:58 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=337623
11/12/29 17:33:58 INFO mapred.JobClient: File Input Format Counters
11/12/29 17:33:58 INFO mapred.JobClient: Bytes Read=1427785
11/12/29 17:33:58 INFO mapred.JobClient: Map-Reduce Framework
11/12/29 17:33:58 INFO mapred.JobClient: Reduce input groups=32956
11/12/29 17:33:58 INFO mapred.JobClient: Map output materialized bytes=466761
11/12/29 17:33:58 INFO mapred.JobClient: Combine output records=32956
11/12/29 17:33:58 INFO mapred.JobClient: Map input records=32118
11/12/29 17:33:58 INFO mapred.JobClient: Reduce shuffle bytes=466761
11/12/29 17:33:58 INFO mapred.JobClient: Reduce output records=32956
11/12/29 17:33:58 INFO mapred.JobClient: Spilled Records=65912
11/12/29 17:33:58 INFO mapred.JobClient: Map output bytes=2387798
11/12/29 17:33:58 INFO mapred.JobClient: Combine input records=251357
11/12/29 17:33:58 INFO mapred.JobClient: Map output records=251357
11/12/29 17:33:58 INFO mapred.JobClient: SPLIT_RAW_BYTES=114
11/12/29 17:33:58 INFO mapred.JobClient: Reduce input records=32956
再度、同じジョブを実行すると次のような結果が表示されます。
WordCount Example
•••••
Job InfoStatus: Failed
Type: jar
Start time: 12/29/2011 5:46:11 PM
End time: 12/29/2011 5:46:13 PM
Exit code: –1Command
call hadoop.cmd jar hadoop-examples-0.20.203.1-SNAPSHOT.jar wordcount /example/data/davinci.txt DaVinciAllTopWords
Output (stdout)
Errors (stderr)
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory DaVinciAllTopWords already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:134)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:830)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:791)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1059)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:791)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:465)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:494)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:67)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:68)
at org.apache.hadoop.util.ProgramDriver.driver(ProgramDriver.java:139)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:64)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.util.RunJar.main(RunJar.java:156)
MapReduceジョブとHDFS管理のためHadoopノードへリモートログイン
Windows AzureでApache Hdoopを起動させれば、メインノード(仮想マシーン)にリモート接続でき、次のような通常タスクを実行することができます。
- Hadoop Map/Reduce ジョブ管理
- HDFS管理
- 普通のネームノード管理タスク
クラスタ管理画面で、ログインするために「Remote Desktop」ボタンを選択します。

クラスタ作成時に選択したのと同じユーザ名とパスワードを使用します。クラスタメインノードVMにログインしたら、最初にすることは、マシンのIPアドレスを確認することです。そして、タスクを実行するためにwebブラウザを開き、IPアドレスと管理ポートを指定して接続します。
- Map/Reduceジョブ用の管理ポートは50030です。
- HDFS管理用ポートは50070です。
Hadoop Map/Reduceジョブ管理を使用するために、http://<ローカルマシーンのIPアドレス>:50030/を使用します。

Hadoopネームノードの詳細は、http://<ローカルマシーンのIPアドレス>:50070/を使用します。

HDFSでファイルを開くために、「Browse File System Link」を選択します。

元情報
- Apache Hadoop on Windows Azure Part 1- Creating a new Windows Azure Cluster for Hadoop Job
- Apache Hadoop on Windows Azure Part 2 – Creating a Pi Estimator Hadoop Job
- Apache Hadoop on Windows Azure Part 3 – Creating a Word Count Hadoop Job with a few twists
- Apache Hadoop on Windows Azure Part 4- Remote Login to Hadoop node for MapReduce Job and HDFS administration
- Apache Hadoop on Windows Azure Part 5 – Running 10GB Sort Hadoop Job with Teragen, TeraSort and TeraValidate Options
Windows Azureトライアルアカウントの支出制限について
「Windows Azure Trial Account Spending Limit」をざっくり意訳した投稿です。
2週間前、マイクロソフトはWindows Azureの新しい機能について幾つかの発表をしました。発表された機能の一つに、サブスクリプションの改良による簡素化されたリスクのない試用版の提供です。超過料金を引き起こす無料クォータを超える使用を制限するようになり、知らずに課金される事態を防止できるようになりました。
支出制限とは?
2011年12月10日以降に新しく有効化した3か月の無料トライアルサブスクリプションとMSDNサブスクライバーのWindows Azure特典は、初期設定で0円の支出制限がかかっています。結果、サブスクリプションで提供されている1か月あたりの無料枠を超過した場合、課金をせずに代わりに来月の課金サイクルで使用メーターがリセットされ、アカウントが再活性化されるまで、サブスクリプションはサスペンドになります。
支出制限について幾つかの微妙な点に気付くかと思います。
- 支出制限する金額を指定することはできない
全ての新しい3か月のトライアルとMSDNサブスクライバーのアカウントには初期設定で、0円以上の支出制限が設定されています。0円の支出制限は、アカウントの無料枠を超える使用が発生する前に、アカウントをサスペンドにするということです。 - 支出制限を解除し、従量課金方式に切り替えることができます。しかし、再度支出制限を有効にすることはできません。
- 3か月の無料トライアルアカウントの支出制限を解除した場合、トライアル期間が終了すると、引き続き従量課金で課金を継続します。支出制限を解除しなかった場合、アカウントは単純に期限切れになります。
- 12月10日以前に有効化したトライアルアカウントとMSDNアカウントには、支出制限は適用されません。
支出制限されていることの確認方法
Windows Azureアカウントのアカウントセンターにアクセスし、サブスクリプションの通知で確認することができます。例えば、次の画像は、3か月のトライアルアカウントを有効化して、数日後に表示されたものです。
(無料トライアルは85日で期限が切れます。アップグレードしますか?)

1か月の無料枠上限に近づいたとき、次の画像の赤枠で囲った部分のように別の通知が表示されます。
(サブスクリプションは、支出制限に近くなりました。支出制限を無効化するには、ここをクリックしてください。)

支出制限に到達すると、サブスクリプション通知が更新されます。
(サブスクリプションは支出制限に到達し、課金を防ぐためにサブスクリプションを無効化しました。支出制限を解除するには、ここをクリックしてください。)

支出制限に到達すると、MSFT*Azure<billing@microsoft.com>からのメールを受け取ることになります。クレジットカードへの課金を防ぐためにアカウントが無効化されたことと、支出制限を解除することでアカウントを継続使用できることが記載れています。
1か月の無料枠の75%、100%、125%に到達したことを知らせるメールは、今後送信されません。2011年12月10日以前にアカウントを有効化した場合、無料枠のどれぐらいを使用したかを確認したい場合は、アカウントセンターで確認してください。
支出制限に到達した場合、何が起こりますか?
支出制限に到達した場合、来月の課金サイクルまでサブスクリプションは無効化されます。アカウントはサスペンドされ、すべてのコンピュートサービスは削除されます。ストレージアカウントは削除されませんが、アクセスすると403エラーが返ってきます。


支出制限を解除する方法
アカウントセンターで、通知の一つを選択することで、支出制限を解除することができます。支出制限を解除すると、従量課金にアップグレードされます。

サブスクリプションをアップグレードすると、アカウントセンターの警告メッセージから支出制限が削除され、サブスクリプションの無料枠を超えた分は課金されます。

アカウントを削除する方法
アカウントが不要になった場合、アカウントセンターにアクセスし、サブスクリプションのキャンセルをクリックしてください。

最終確認ダイアログが表示されます。

キャンセルしたアカウントは、アカウントセンターで次のように表示されます。

Windows Azure管理ポータルでは、次のように無効化されます。

VS2010からAzureにデプロイがちょびっと変わったよ!
Windows Azure SDK for .NET11月版がリリースされました。VS Toolsもいくつか変更が入ったようです。
てことで、一年ぶりぐらいにAzureにでぽろーーーい!してみましょうかね。
Visual Studio上で、ほぼほぼ完結できるようになっています。
証明書もばっちりGUIで作成でき、複数のサブスクリプションを管理できて配置先も簡単に選べる。
ホステッドサービスの作成、ストレージアカウントの作成もVS上でできちゃいませ!旦那
リモートデスクトップの設定もチェックボックスにチェック入れれば、設定画面でますよ。
あ、そうそう。Windows Azure SDK名称変わったから。Windows Azure SDK for .NETに。
あっちこちの人がうげっと呻きそうですねw







![SNAGHTML170f888[4]](https://sqlazure.jp/b/wp-content/uploads/2011/11/SNAGHTML170f8884.png "SNAGHTML170f888[4]")





Windows Azure Platform PowerShell Cmdlets V2.0インストール時にエラーが出た時の対応方法
「Windows Azure Platform PowerShell Cmdlets V2.0 を使ってみる」で紹介されているように、インストール時にエラーが出ることがある。
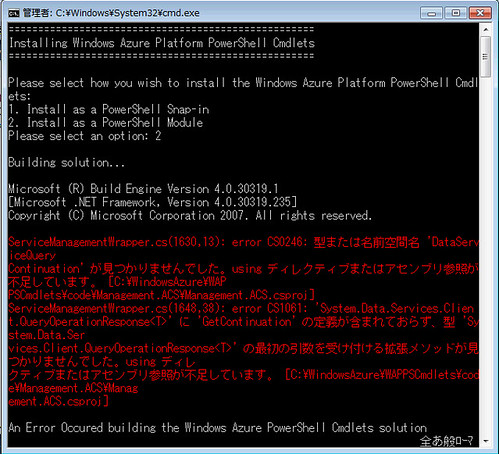
CS0246:型または名前空間 ‘DataServiceQuery Contrinuation’が見つかりませんでした。 using ディレククティブまたはアセンブリ参照が不足しています。
さて、引用元で解決策が提示されているのですが、ちょーっとまった!
これ、既知の問題みたいで対応策が公式サイトのドキュメントで提示されています。
http://wappowershell.codeplex.com/documentationにアクセスし、最下部に説明が記載されている。

もう少しわかりやすく書いてほしいですね!!
このエラーが出た場合は、ADO.NET Data Servicesの更新パッチを当ててねとのことらしい。
をインストールすると、改善する可能性があるようです。